作者:@akshay_pachaar
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
你可能已经开发过聊天机器人,甚至可能用一些工具搭建了一个 ReAct 循环 (ReAct:Reason + Act,一种让模型在行动前先进行推理的模式)。跑 Demo 的时候看着挺好,但一旦投入生产环境,系统就会开始掉链子:模型会忘记三步前做了什么,工具调用悄悄报错,上下文窗口(Context Window)里塞满了毫无意义的垃圾信息。
问题其实并不在模型本身,而在模型外围的基础设施。
LangChain 证明了这一点:他们仅仅通过改变包裹大语言模型的底层架构——模型没变,参数没变——就让系统在 TerminalBench 2.0 (一个衡量 AI 智能体处理命令行任务能力的权威基准测试) 上的排名从 30 名开外飙升到了第 5 名。另一项研究则通过让大语言模型自己去优化这套架构,实现了 76.4% 的通过率,甚至超过了人类精心设计的系统。
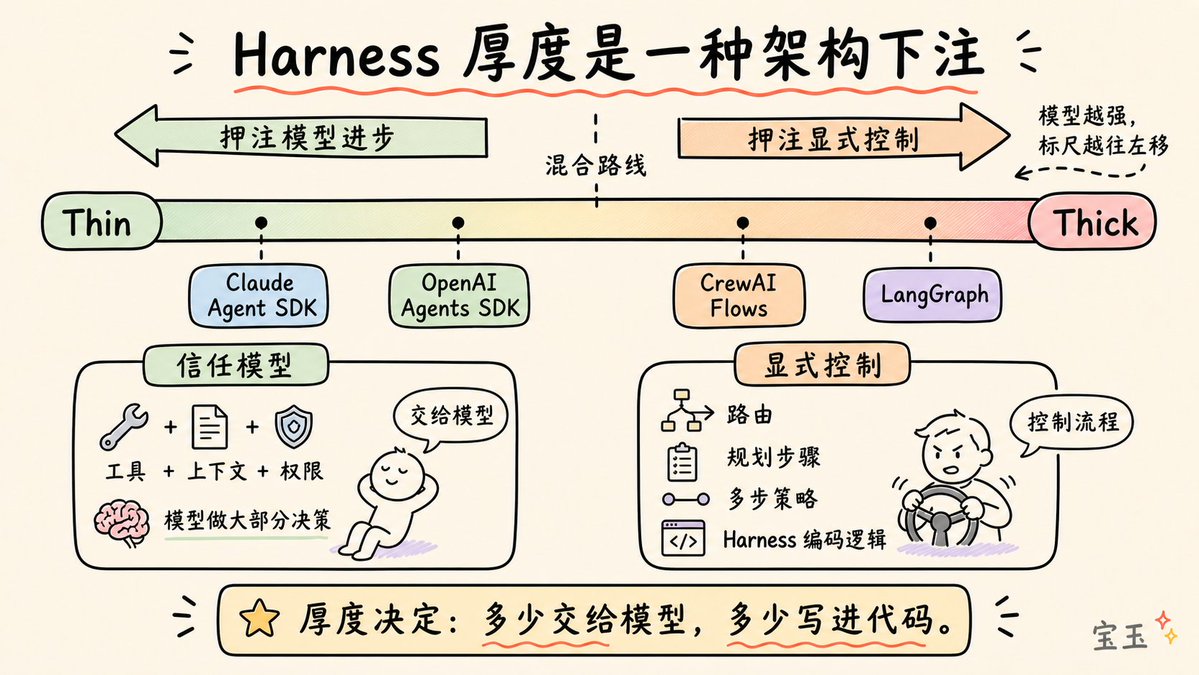
现在,这套基础设施有了一个正式的名字:AI Agent Harness。
虽然这个术语在 2026 年初才正式确立,但其核心理念早已存在。Harness是包裹在大语言模型之外的完整软件架构:它包括编排循环、工具、记忆、上下文管理、状态持久化、错误处理和护栏(Guardrails)。Anthropic 在其 Claude Code 文档中直截了当地指出:SDK(软件开发工具包)就是“驱动 Claude Code 的 Agent Harness”。OpenAI 的 Codex 团队也使用了同样的说法,明确将“智能体”和“Harness”等同,指代那些让大语言模型真正发挥作用的非模型架构。
我非常喜欢 LangChain 的 Vivek Trivedy 给出的定义公式:“如果你不是模型本身,那你就是 Harness。”
这里有一个经常让人搞混的区别:“AI 智能体”(Agent)是用户感知到的行为体现,它是一个有目标、会用工具、能自我纠错的实体;而“Harness”则是产生这种行为的背后机器。当有人说“我开发了一个智能体”时,他真正的意思是“我开发了一套 Harness,并把它接入了模型”。
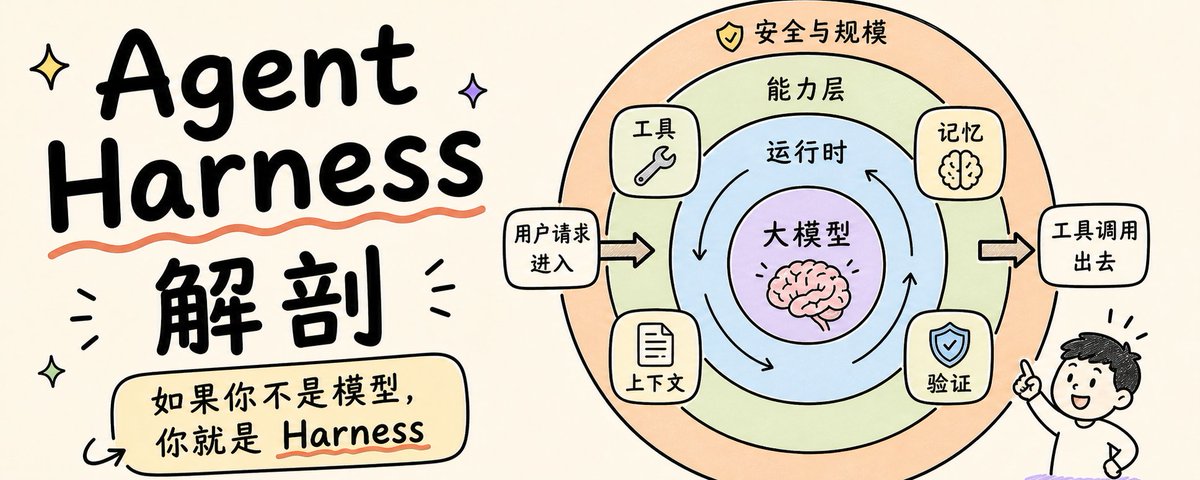
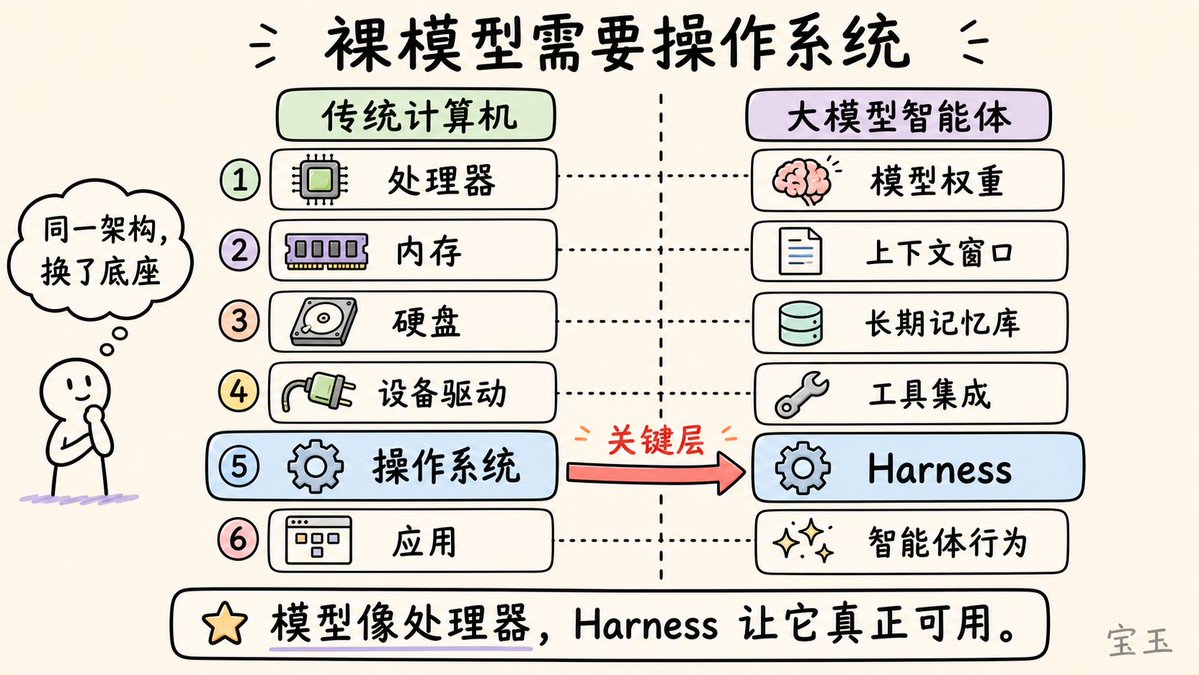
Beren Millidge 在其 2023 年的博文中做了一个精准的类比:原生大语言模型就像一个没有内存、没有硬盘、也没有输入输出设备的 CPU。此时,上下文窗口充当了内存(快但容量有限),外部数据库扮演了硬盘(大但速度慢),工具集成则是设备驱动程序。而Harness,就是那个操作系统。正如 Millidge 所写:“我们重新发明了冯·诺依曼架构(Von Neumann architecture)”,因为这是任何计算系统最自然的抽象方式。
围绕模型,工程化可以分为三个同心圆层次:
Harness 不仅仅是一个包裹提示词的套壳(AI Wrapper),它是让智能体能够自主行动的完整系统。
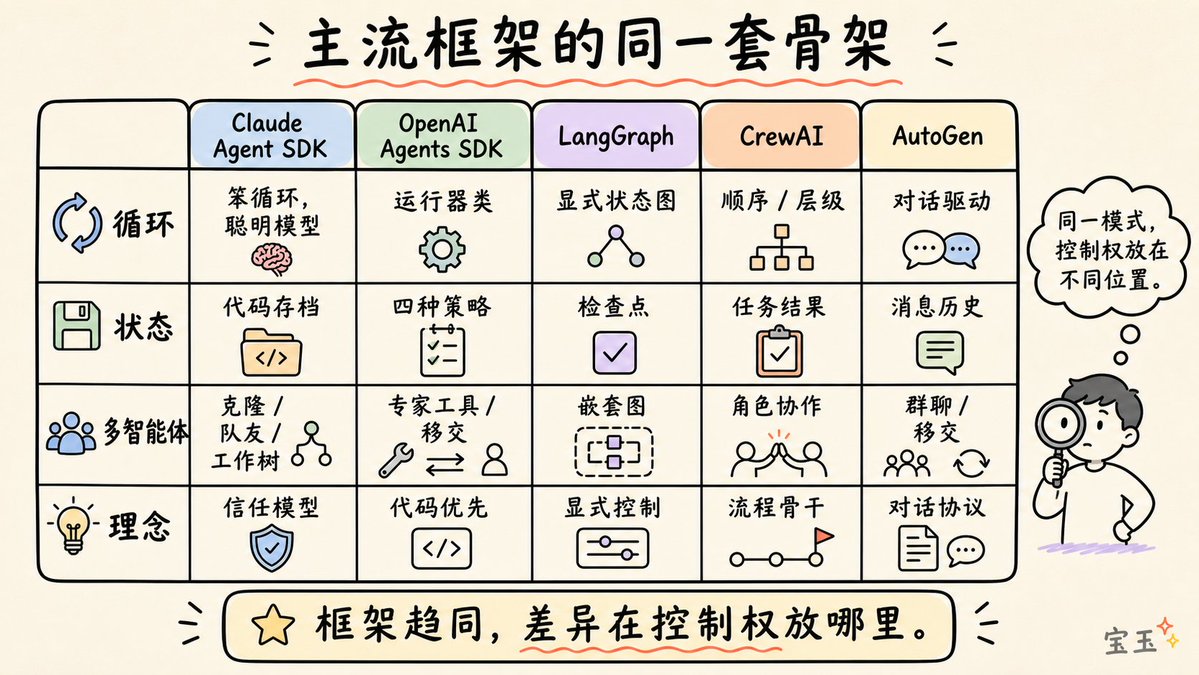
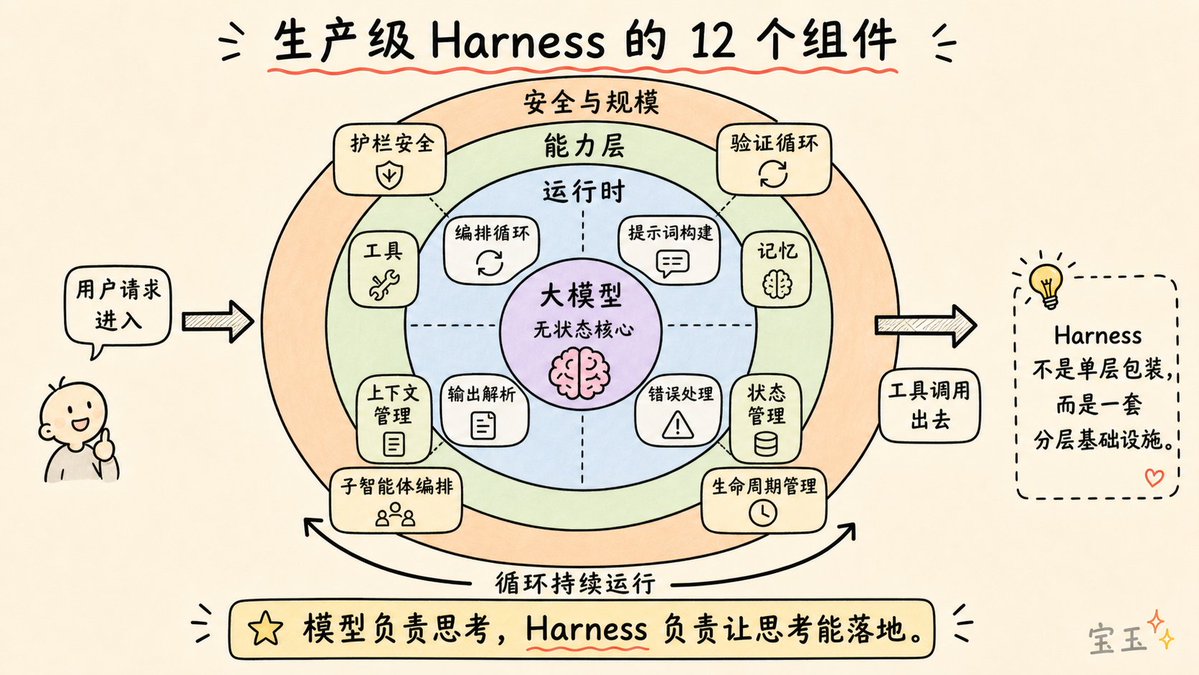
综合 Anthropic、OpenAI、LangChain 以及广大从业者的实践经验,一个生产级的 Agent Harness 由 12 个不同的组件构成。让我们逐一拆解。
1. 编排循环 (The Orchestration Loop)
这是系统的“心脏”。它实现了“思考 - 行动 - 观察”(Thought-Action-Observation,简称 TAO)循环,也被称为 ReAct 循环。这个循环不停运转:整合提示词 -> 调用大语言模型 -> 解析输出 -> 执行工具调用 -> 反馈结果 -> 重复,直到任务完成。
从技术实现上看,它通常只是一个 while 循环。但复杂的地方不在于循环本身,而在于循环所要处理的各种状态和逻辑。Anthropic 将他们的运行时描述为一个“笨循环”,所有的智慧都存在于模型之中,Harness 只负责管理回合的切换。
2. 工具 (Tools)
工具是智能体的“双手”。它们被定义为某种结构化模式(名称、描述、参数类型),并注入到模型的上下文中,让模型知道哪些工具可用。工具层负责注册、格式校验、参数提取、在沙箱(Sandbox)环境执行、结果捕获,并最终将结果格式化为模型可读的“观察结果”。
Claude Code 提供了六大类工具:文件操作、搜索、执行、网页访问、代码分析和子智能体创建。OpenAI 的 Agents SDK 则支持函数工具(通过 @function_tool 定义)、托管工具(如网页搜索、代码解释器、文件搜索)以及 MCP (Model Context Protocol,一种开放的工具接入标准) 服务器工具。
3. 记忆 (Memory)
记忆在不同的时间尺度上运作。短期记忆是单次会话中的对话历史。长期记忆则跨越多个会话持久存在:Anthropic 使用项目文件和自动生成的 memory.md 文件;LangGraph 使用按命名空间组织的 JSON 存储;OpenAI 则支持由 SQLite 或 Redis 驱动的会话存储。
Claude Code 实现了三层记忆架构:一个轻量级索引(每条约 150 字符,始终加载)、按需调用的详细主题文件,以及仅通过搜索访问的原始对话记录。一个核心设计原则是:智能体将自己的记忆视为一种“提示”,在行动前必须根据实际状态进行验证。
4. 上下文管理 (Context Management)
这是许多智能体容易暗中翻车的地方。核心问题在于上下文腐烂:当关键信息处于窗口中间位置时,模型表现会下降 30% 以上(这就是斯坦福大学发现的“迷失在中间”现象)。即便是支持百万级 Token (Token:模型处理文本的最小单位,大致相当于单词或汉字的部分) 的窗口,随着上下文的增长,指令遵循能力也会退化。
生产环境的应对策略包括:
Anthropic 的上下文工程指南指出,目标是:找到能最大化达成目标概率的、信号最强的最小 Token 集合。
5. 提示词构建 (Prompt Construction)
这决定了模型在每一步具体能看到什么。它是层级化的:系统提示词、工具定义、记忆文件、对话历史,以及当前的用户消息。
OpenAI 的 Codex 使用严格的优先级栈:服务器控制的系统消息(最高优先级)、工具定义、开发者指令、用户指令,最后才是对话历史。
6. 输出解析 (Output Parsing)
现代 Harness 依赖于原生工具调用,即模型返回结构化的 tool_calls 对象,而不是需要费力解析的自由文本。Harness 会检查:是否有工具调用?如果有,执行并继续循环;如果没有,那当前的输出就是最终答案。
对于结构化输出,OpenAI 和 LangChain 都支持通过 Pydantic 模型 (Python 中用于数据校验和格式化的库) 进行模式约束。
7. 状态管理 (State Management)
LangGraph 将状态模拟为在图形节点中流动的类型化字典。系统会在关键步骤进行“存档”(Checkpointing),这样即使中断也能恢复,甚至可以进行“时间旅行”式的调试。OpenAI 则提供了四种策略:应用内存、SDK 会话、服务器端 API 或轻量级的响应 ID 链。Claude Code 采用了不同的思路:将 Git 提交作为存档点,将进度文件作为结构化的草稿纸。
8. 错误处理 (Error Handling)
为什么这很重要?一个包含 10 个步骤的过程,即使每一步的成功率高达 99%,最终全流程的成功率也只有约 90.4%。错误是会滚雪球的。
LangGraph 将错误分为四类:临时性的(带延迟的重试)、模型可恢复的(将错误作为工具消息返回,让模型自己调整)、用户可修复的(暂停等待人类干预)以及意外错误(上报调试)。
9. 护栏与安全 (Guardrails and Safety)
OpenAI 的 SDK 实现了三个层级:输入护栏(在第一个智能体运行时检查)、输出护栏(检查最终结果)以及工具护栏(每次调用工具前检查)。一旦触发“绊网”(Tripwire)机制,智能体将立即停止。
Anthropic 在架构上将“权限执行”与“模型推理”分离。模型决定想做什么,但 Harness 决定允许做什么。
10. 验证循环 (Verification Loops)
这是区分“玩具演示”和“生产级智能体”的关键。Anthropic 推荐三种方法:基于规则的反馈(测试、代码检查)、视觉反馈(通过 Playwright 截取 UI 截图)以及以大语言模型为裁判 (LLM-as-judge)(由另一个子智能体评估输出)。
Claude Code 的创造者 Boris Cherny 指出,让模型能够验证自己的工作,能让产出质量提升 2 到 3 倍。
11. 子智能体编排 (Subagent Orchestration)
Claude Code 支持三种模式:克隆 (Fork)(复制父级上下文)、队友 (Teammate)(通过文件邮箱通信的独立窗口)和 工作树 (Worktree)(独立的 Git 分支)。OpenAI 则支持将智能体作为工具(专家处理特定子任务)或移交(专家接管后续控制权)。
既然了解了组件,让我们看看它们在一次循环中是如何协同工作的。
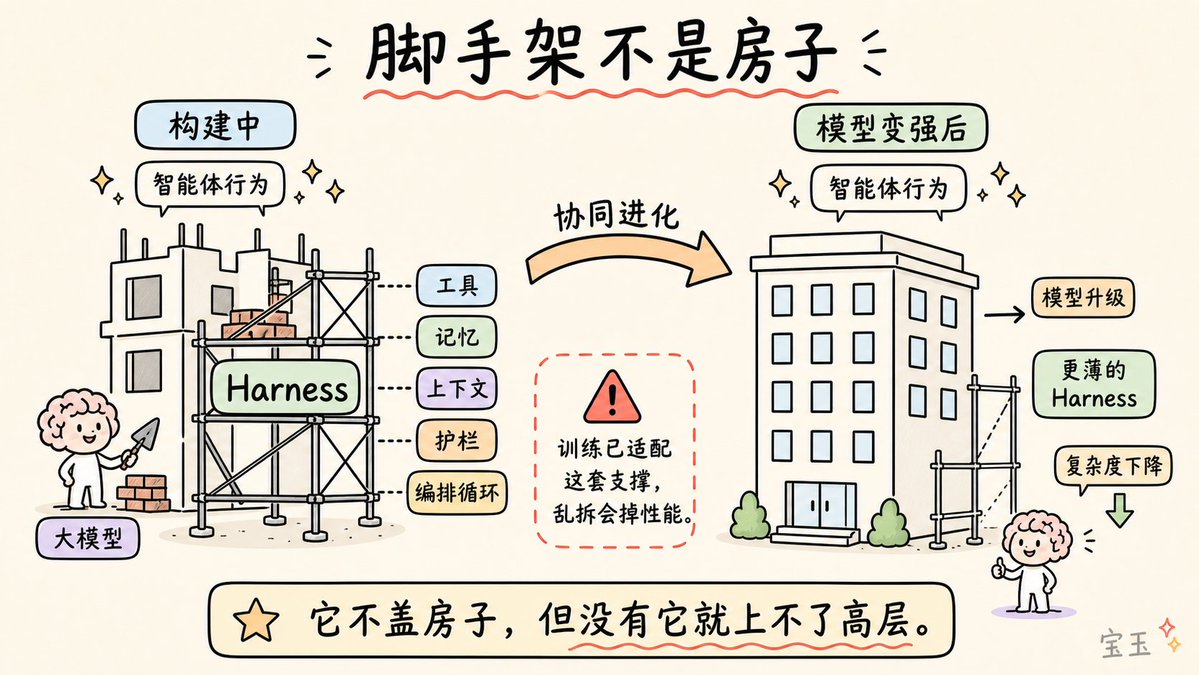
“脚手架”这个比喻并非装饰,而是极其精准的。建筑脚手架是临时性的基础设施,让工人们能触及原本够不到的高度。脚手架本身不盖房子,但没有它,工人就上不去高层。
关键洞察在于:房子盖好后,脚手架是要拆除的。 随着模型能力的提升,Harness 的复杂程度应该逐渐降低。
这就是协同进化原则:现在的模型在训练时,就已经考虑了 Harness 的存在。如果你的 Harness 设计得好,当模型升级时,你不需要增加复杂度,性能就会自动提升。
每个 Harness 的架构师都面临这七个选择:
两个使用完全相同模型的智能体,性能可能天差地别,原因就在于 Harness 的设计。TerminalBench 的证据已经非常明确:仅仅改变 Harness,就能让排名变动 20 多位。
Harness 不是一个已经解决的问题,也不是一个通用的商品层。它是硬核工程能力的体现:如何将上下文视为稀缺资源进行管理?如何设计验证循环以防止错误累积?如何构建不产生幻觉的记忆系统?
随着模型越来越强,Harness 会变薄,但它永远不会消失。即便最强大的模型,也需要系统来管理窗口、执行代码、保存状态并验证工作。
下次当你的智能体表现不佳时,别光顾着抱怨模型,去检查一下你的Harness吧。
著者:@akshay_pachaar
本記事では、Anthropic、OpenAI、Perplexity、LangChainが実際に何を開発しているのかを深掘りします。オーケストレーションループ、ツール、メモリ、コンテキスト管理、そして「ステートレス」なLLMを全能のエージェントへと変貌させる基盤メカニズムについて解説します。
チャットボットを開発したことがある方、ReActループをツールで構築したことがある方——デモではうまく動いても、本番環境では、モデルが3ステップ前のことを忘れ、ツール呼び出しが静かに失敗し、コンテキストウィンドウが無意味なゴミで埋め尽くされます。
問題はモデル自体ではなく、モデルを包むインフラストラクチャにあります。
LangChainはこれを証明しました:モデルもパラメータも変えずに、LLMを包むアーキテクチャを変更しただけで、TerminalBench 2.0の順位を30位圏外から5位に急上昇させました。別の研究ではLLM自身にこのアーキテクチャを最適化させることで76.4%の通過率を達成し、人間が設計したシステムを上回りました。
このインフラストラクチャには正式名称がつきました:AI Agent Harness。
2026年初頭に正式に確立された用語ですが、中核概念は以前から存在。HarnessはLLMを包む完全なソフトウェアアーキテクチャであり、オーケストレーションループ、ツール、メモリ、コンテキスト管理、状態永続化、エラー処理、ガードレールを含みます。AnthropicはSDKを「Claude Codeを駆動するAgent Harness」と明言。OpenAIのCodexチームも「エージェント」と「Harness」を同一視しています。
LangChainのVivek Trivedyによる定義:「モデル自身でなければ、あなたはHarnessである。」
混同されがちな区別:「AIエージェント」はユーザーが知覚する振る舞い——目標を持ち、ツールを使い、自己修正できる実体。「Harness」はその振る舞いを生み出す背後機構。「エージェントを開発した」と言うとき、本当の意味は「Harnessを開発してモデルに接続した」です。
Beren Millidgeの2023年の比喩:生のLLMはメモリもハードディスクもI/OデバイスもないCPUのようなもの。コンテキストウィンドウがメモリ(高速だが容量限定)、外部DBがハードディスク(大容量だが低速)、ツール統合がデバイスドライバ。そしてHarnessがOS。「私たちはフォン・ノイマンアーキテクチャを再発明した」。
モデルを中心とした3層構造:プロンプトエンジニアリング(指示の設計)、コンテキストエンジニアリング(タイミングと内容の管理)、Harnessエンジニアリング(上記2つ+アプリケーションアーキテクチャ全体:ツール編成・状態永続化・エラー復旧・検証ループ・安全実行・ライフサイクル管理)。Harnessは単なるAI Wrapperではなく、エージェント自律行動のための完全システムです。
12のコンポーネント
1. オーケストレーションループ:システムの心臓。思考-行動-観察(TAO)サイクルを実装。Anthropicはこれを「愚直なループ」と表現。
2. ツール:エージェントの手。構造化スキーマ(名前・説明・パラメータ型)で定義され、サンドボックスで実行。Claude Codeは6種、OpenAI Agents SDKは関数ツール+マネージドツール+MCP対応。
3. メモリ:短期(セッション内履歴)+長期(セッション横断)。Claude Codeは3層(軽量インデックス+詳細ファイル+検索専用アーカイブ)。設計原則:エージェントは自分の記憶を「ヒント」と見なし、行動前に実状態で検証する。
4. コンテキスト管理:「Lost in the Middle」現象——重要情報がウィンドウ中間にあるとパフォーマンス30%以上低下。対策:圧縮・観測マスキング・ジャストインタイム検索・サブエージェント委任。
5. プロンプト構築:階層構造(システムプロンプト→ツール定義→メモリ→履歴→ユーザーメッセージ)。OpenAI Codexは厳格な優先度スタック。
6. 出力解析:ネイティブツール呼び出し(構造化tool_callsオブジェクト)。構造化出力はPydanticモデルで制約。
7. 状態管理:LangGraphは型付き辞書+チェックポインティング。OpenAIは4戦略。Claude CodeはGitコミットをチェックポイントに。
8. エラー処理:10ステップ各99%成功率でも全体は約90.4%。LangGraphは4分類(一時的/モデル回復可能/ユーザー修復可能/予期せぬエラー)。
9. ガードレールと安全性:OpenAIは入力/出力/ツールの3層チェック。Anthropicは「権限実行」と「モデル推論」を分離。モデルがしたいことを決め、Harnessが許可することを決める。
10. 検証ループ:ルールベース+ビジュアル(Playwrightスクリーンショット)+LLM-as-judge。Boris Cherny:モデルに自己検証させると品質が2〜3倍向上。
11. サブエージェント編成:Claude CodeはFork/Teammate/Worktree。OpenAIはツールとして/移譲として。
12. 実行サイクル:プロンプト組立→モデル推論→出力分類→ツール実行→結果パッケージ→コンテキスト更新→ループ。
主要実装:Anthropic (Claude Agent SDK)はシンプルなquery()関数。OpenAI (Agents SDK)はコードファースト。LangGraphは明示的状態グラフ。CrewAIはロールベース協調。AutoGen(Microsoft)は複数編成モード。
「足場」という比喩は極めて正確。建築足場は一時的インフラ。家が建ったら足場は撤去する——モデル能力向上とともにHarnessの複雑さは低減すべき。これが共進化の原則:優れたHarnessならモデルアップグレード時に複雑さを追加せずに性能が自動向上。
7つの選択:単一vs.マルチエージェント(まず単一を極める)/ ReAct vs. 計画先行 / コンテキスト管理戦略 / 検証ループ設計 / 権限と安全 / ツール範囲(最小セットが最適)/ Harnessの厚み(何を固定し何をモデルに委ねるか)。
同一モデルでもHarness設計で性能は天と地。TerminalBenchの証拠:Harness変更だけで20位以上変動。Harnessは解決済みの問題でも汎用コモディティでもない。コンテキストを希少資源として管理し、検証ループでエラー蓄積を防ぎ、幻覚のないメモリシステムを構築する——ハードコアな工学能力の結晶です。
モデルが強くなるほどHarnessは薄くなるが、決して消えない。次にエージェントのパフォーマンスが悪いときは、モデルを責める前にHarnessを点検してください。